Bring in the clones
Two central and related questions I will be addressing as part of this VR Experience are:
1) How one can move a typically non-diegetic element (the narrator) to a diegetic element in a VR.
2) Whether one can effectively employ mechanisms such as voice cloning / text to speech APIs for the voice of the Storyteller (and perhaps other characters).
The advantage of such an approach (Voice Cloning / Text to Speech) would be that the story script can be adapted, and new audio generated dynamically without the need for re-recording voice talent. Together with AI elements (voice interaction by the user and responses / actions / intents) decoupling these elements from the core environment built (in the case of this project in Unity means the story and AI can enhanced over time without having to rebuild and rerelease the experience as a whole.
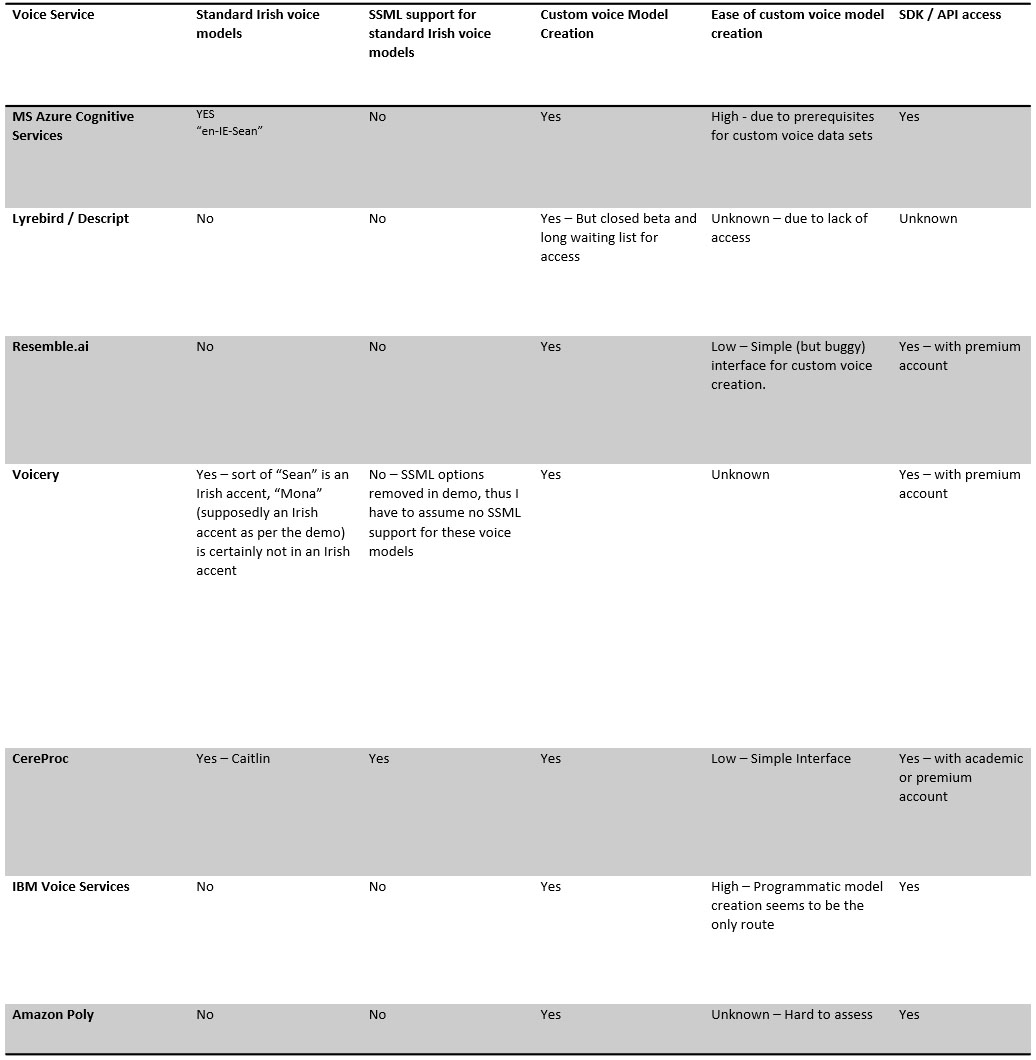
With this in mind, I have evaluated a number of AI based voice Cloning solutions and Text to Speech services. Assessing their support for Irish accents through existing “standard” voice models, Standard “Irish” voice model Support for SSML, support for custom voice creation, and ease of custom voice creation, and SDK / API access.
Why would you use standard voice models?
Whilst building custom voices is desirable, support for Irish voice models (even though there is of course no single “Irish” accent) via standard voice models is very important given multiple characters (beyond the narrator) that need to be included in the VR Experience I am building.
SSML
Another important factor is support for SSML (Speech Synthesis Markup Language). SSML allows for customization of a voice model including emphasis on specific words and sentences, pauses, pitch etc. Without this ability, the results are rather monotone.
Ease-of-Use
Whilst ease-of-use may not seem like the most significant concern, I believe it is when examining the practicalities of using cloned voices in a VR game or Experience. Furthermore the focus of this project is not primarily concerned with programmatic voice model generation of investigating voice-cloning systems in-depth. Where any voice cloning / text to speech service is targeting game and multimedia design and development agencies, the lack of a simple interface to allow voice talent (the voices to be cloned) to record samples is a major flaw in the process. Therefore, I think IBM, Amazon, and MS have work to do here.
Resemble.ai provide a simple interface for custom voice creation online, albeit rather buggy in its current state. Batches of audio samples were not saved by the system, and the system kept demanding more and more audio samples (over 200 were recorded via the system) where 50 should suffice. Additionally, the generated custom voice needed some clean-up and the results are a little disappointing.
SAMPLE RESULTS
The generated voice, when compared to the original, sounds like a slightly depressed drunk robot. This may be due to the lack of support for SSML with custom voices. Or at least with the generated custom voice in question. This appears to be another issue in the system as SSML is supported in the editor interface, but the voice cannot be generated where emphasis tags are used.
Here is a sample of the REAL VOICE ACTOR:
Here is the RESEMBLE.AI CLONED VOICE / system generated sample
(no SSML due to issues):
I hope the above results can be improved upon and the SSML issues fixed. Resemble.ai have a nice system but it does need improvement, and from my perspective, the pricing model needs rethinking quite drastically.
Based on my assessment to date, the Edinburgh base CercProc (members of their team are University of Edinburgh alumni) offer the best solution in terms of standard Irish voice support. I have yet to fully test voice creation. Furthermore, they offer access under an academic license.
Given the need to support a range of characters, I may use both MS Azure, Resemble.ai and CercProc generated voices, as well as voice actor recordings in the final project. This will also be useful for comparative evaluation.

